Working With Algorithms
Goal
This guide demonstrates how to execute graph algorithms and work with their results using RelationalAI’s SQL Graph Library for Snowflake.
Introduction
After you create a graph, you may execute algorithms on that graph using the various functions described in the Overview of Graph Algorithms. This guide explains how to:
You can find several examples of the patterns in practice in the Examples section, including how to:
Executing Algorithms
When you call an algorithm function from RelationalAI’s SQL Graph Library, all of the computation happens in RAI — not in Snowflake. The function blocks until the results of the algorithm are returned to Snowflake from RAI.
This section describes the concepts associated with running graph algorithms in RAI from Snowflake.
RAI Engines
Executing algorithms on a graph requires a RAI engine.
You can either set the engine in a
RAI context
with the
use_rai_engine
procedure, or provide the name of the engine to the function’s
arguments parameter:
-- Set the RAI context.
CALL RAI.use_rai_database('my_rai_db');
CALL RAI.use_rai_engine('my_rai_engine');
-- Create an undirected graph with three nodes and two edges.
CREATE TABLE my_edges(x INT, y INT) AS SELECT * FROM VALUES (1, 2), (2, 3);
CALL RAI.create_data_stream('my_edges');
CALL RAI.create_graph('my_graph', 'my_edges');
-- Get the number of nodes in `'my_graph'`.
-- The engine `'my_rai_engine'` from the RAI context is used,
-- since no engine name is explicitly provided.
SELECT RAI.num_nodes('my_graph')
/*+---+
| 3 |
+---+ */
-- Get the number of edges in `'my_graph'` using an engine that is different
-- from the engine set in the RAI context. The engine name `'my_other_rai_engine'`
-- is explicitly provided to the function.
SELECT RAI.num_edges('my_graph', {'rai_engine': 'my_other_rai_engine'});
/*+---+
| 2 |
+---+ */If no engine with the provided name exists, an error is returned and the algorithm is not executed. See Required Versus Optional Arguments for more information on function arguments.
Scalar Versus Tabular Functions
Some algorithms return a scalar value — such as
min_degree,
which returns the minimum degree of a graph.
Other functions return a table — such as
degree,
which returns the degree of each node.
Tabular functions must be called with SELECT * FROM TABLE(...),
as in the following example:
-- Create an undirected graph with three nodes and two edges.
CREATE TABLE my_edges(x INT, y INT) AS SELECT * FROM VALUES (1, 2), (2, 3);
CALL RAI.create_data_stream('my_edges');
CALL RAI.create_graph('my_graph', 'my_edges');
-- Compute the minimum degree of `'my_graph'`.
-- The return value is a scalar.
SELECT RAI.min_degree('my_graph');
/*+---+
| 1 |
+---+ */
-- Find the degree of each node in `'my_graph'`.
-- The return value is a table.
SELECT * FROM TABLE(RAI.degree('my_graph'));
/*+------+--------+
| NODE | DEGREE |
|------+--------+
| 1 | 1 |
| 2 | 2 |
| 3 | 1 |
+------+--------+ */The table returned by tabular functions has named columns
to help identify the meaning of each row.
For example, the table returned by the degree function
has a node column and a degree column,
since each row pairs a node with its degree.
See
Results Schema
for more information.
Required Versus Optional Arguments
Every algorithm function has two parameters:
graph_name: the name of the graph on which to execute the algorithm.arguments: a JSON object containing additional arguments.
The graph_name is always required.
Some functions, like the
min_degree
and
degree
functions in the preceding section’s example,
do not require an arguments object.
Other algorithms, such as
shortest_path_length,
do require arguments to be provided:
-- Create an undirected graph with three nodes and two edges.
CREATE TABLE my_edges(x INT, y INT) AS SELECT * FROM VALUES (1, 2), (2, 3);
CALL RAI.create_data_stream('my_edges');
CALL RAI.create_graph('my_graph', 'my_edges');
-- Compute the distance between node 1 and every other node in the graph.
-- `shortest_path_length` requires a `'source' node to be specified in the
-- arguments object.
SELECT * FROM TABLE(RAI.shortest_path_length('my_graph', {'source': 1}));
/*+--------+--------+--------+
| SOURCE | TARGET | LENGTH |
|--------+--------+--------|
| 1 | 1 | 0 |
| 1 | 2 | 1 |
| 1 | 3 | 2 |
+--------+--------+--------+ */If you call a function that requires an arguments object with only the graph name,
Snowflake displays an error:
-- The required `'source'` node is missing, so an error is returned.
SELECT * FROM TABLE(RAI.shortest_path_length('my_graph'));
/* +----------------------------------------------------------------+
| Invalid argument types for function 'RAI.SHORTEST_PATH_LENGTH' |
+----------------------------------------------------------------+ */Required arguments for each function are documented in the SQL Library Reference. You may access each algorithm’s reference documentation by clicking the function name in the Overview of Graph Algorithms.
Array Arguments
In many cases, arguments that accept a node
— such as the
shortest_path_length
function’s source argument,
or the
degree
function’s node argument —
can also accept an array of nodes.
For instance, when an array of two or more nodes is passed to
the degree function’s node argument,
the degrees of each node in the array are returned:
-- Create an undirected graph with three nodes and two edges.
CREATE TABLE my_edges(x INT, y INT) AS SELECT * FROM VALUES (1, 2), (2, 3);
CALL RAI.create_data_stream('my_edges');
CALL RAI.create_graph('my_graph', 'my_edges');
-- Get the degree of node 2 in `'my_graph'`.
-- A single node is provided to the `'node'` argument.
SELECT * FROM TABLE(RAI.degree('my_graph'), {'node': 2})
/*+------+--------+
| NODE | DEGREE |
|------+--------+
| 2 | 2 |
+------+--------+ */
-- Get the degree of nodes 1 and 3 in `'my_graph'`.
-- Both nodes are provided to the `'node'` argument in an array.
SELECT * FROM TABLE(RAI.degree('my_graph'), {'node': [1, 3]});
/*+------+--------+
| NODE | DEGREE |
|------+--------+
| 1 | 1 |
| 3 | 1 |
+------+--------+ */Some functions, such as the shortest_path_length function,
can accept multiple array arguments.
For example, you may call shortest_path_length with arrays
provided to both its source and target arguments:
-- Compute the length of a shortest path in `'my_graph'` starting at either
-- node 1 or node 2 and ending at either node 3 or node 4.
SELECT * FROM TABLE(RAI.shortest_path_length('my_graph', {'source': [1, 2], 'target': [3, 4]}));
/*+--------+--------+--------+
| SOURCE | TARGET | LENGTH |
|--------+--------+--------|
| 1 | 3 | 2 |
| 1 | 4 | 3 |
| 2 | 3 | 1 |
| 2 | 4 | 2 |
+--------+--------+--------+ */When multiple arrays are passed to two or more arguments,
rows containing all possible node combinations are returned.
For example, in the preceding statement, the array [1, 2] is passed to the source argument
and the array [3, 4] is passed to the target argument.
The table contains rows for all possible (source, target) pairs containing
nodes from the arrays: (1, 3), (1, 4), (2, 3), and (2, 4).
Many functions accept a tuples argument that can be used to
compute the desired value for specific node combinations.
For example, to compute the shortest path length between
the (source, target) pairs (1, 3) and (2, 3), you need to pass the array
[[1, 3], [2, 3]] to the tuples argument:
-- Compute the shortest path length in `'my_graph'` between nodes 1 and 3
-- and nodes 2 and 3 using the `'tuples'` argument.
SELECT * FROM TABLE(RAI.shortest_path_length('my_graph', {'tuples': [[1, 3], [2, 3]]]}));
/*+--------+--------+--------+
| SOURCE | TARGET | LENGTH |
|--------+--------+--------|
| 1 | 3 | 2 |
| 2 | 3 | 1 |
+--------+--------+--------+ */Arguments that accept arrays are documented in the SQL Library Reference. See the Overview of Graph Algorithms to access each function’s reference documentation.
Scheduled Tasks
Algorithms may be executed as a
Snowflake task (opens in a new tab).
As such, you may schedule algorithms to run on specific dates and times
or repeat with predetermined intervals.
In the following example, the pagerank algorithm is executed every five minutes
and the results are stored in a Snowflake table:
-- Create a task.
CREATE OR REPLACE TASK run_pagerank
WAREHOUSE = my_sf_warehouse
SCHEDULE = '5 MINUTE'
AS
BEGIN
SELECT * FROM TABLE(RAI.pagerank('my_graph', {
'rai_engine': 'my_rai_engine',
'result_table': '<my_sf_db>.<my_sf_schema>.pagerank_results'
}));
END;
-- Start the recurring task.
ALTER TASK run_pagerank RESUME;
-- After five minutes, the results are available.
SELECT * FROM pagerank_results;When executing an algorithm in a task, you must:
-
Specify the Snowflake warehouse that executes the task.
-
Provide an engine name to the algorithm’s
rai_engineargument, even if you have previously set a RAI context since the task cannot access the current session variables when it is executed. -
Provide the fully qualified (opens in a new tab) name of a Snowflake table in which the results of the algorithm will be stored to the algorithm’s
result_tableargument.
Limitations
Executing algorithms takes time and, for large enough graphs, the execution time may exceed statement timeouts set for your Snowflake account. If you encounter timeouts, contact your Snowflake administrator to request an increase to your timeout limits.
Working With Results
Once an algorithm has run and the results are in Snowflake, you’ll want to do something with those results. This section describes concepts associated with using the results of algorithms run in RAI.
Results Schema
Tabular functions, such as
degree,
return tables with named columns.
For instance, degree returns a table with a node column and a degree column:
-- Create an undirected graph with three nodes and two edges.
CREATE TABLE my_edges(x INT, y INT) AS SELECT * FROM VALUES (1, 2), (2, 3);
CALL RAI.create_data_stream('my_edges');
CALL RAI.create_graph('my_graph', 'my_edges');
-- Find the degree of each node in `'my_graph'`.
-- The return value is a table with two columns named NODE and DEGREE.
SELECT * FROM TABLE(RAI.degree('my_graph'));
/*+------+--------+
| NODE | DEGREE |
|------+--------+
| 1 | 1 |
| 2 | 2 |
| 3 | 1 |
+------+--------+ */The schema for each algorithm’s return table is available in the Overview of Graph Algorithms.
Saving Results in Snowflake
There are two ways to store the results of an algorithm in a Snowflake table:
CREATE_TABLE
You can execute an algorithm and create a table from the results
using the
CREATE TABLE (opens in a new tab)
command:
-- Compute the degree of each node in `'my_graph'` and store the results
-- in a Snowflake table named `'my_results_table'`. Rather than using
-- the `result_table` argument, the table is created directly.
CREATE OR REPLACE TABLE my_result_table(node INT, degree INT) AS (
SELECT * FROM RAI.degree('my_graph')
);
-- The result table has the correct schema.
SELECT * FROM my_result_table;
/*+------+--------+
| NODE | DEGREE |
|------+--------+
| 1 | 1 |
| 2 | 2 |
| 3 | 1 |
+------+--------+ */The schema of my_result_table should match the algorithm’s
result schema.
In the preceding example, this means that the table should have a node
and degree column, both of which are integers, since that is the schema of
the table returned by the degree function.
result_table
You may execute an algorithm and store the results in a Snowflake table
by providing the table’s
fully qualified (opens in a new tab)
name to the algorithm’s result_table argument:
-- Compute the degree of each node in `'my_graph'` and store the results
-- in a Snowflake table named `'my_result_table'`. Note that the function
-- returns an empty table when `result_table` is set.
SELECT * FROM TABLE(RAI.degree(
'my_graph', {'result_table': '<my_sf_db>.<my_sf_schema>.my_result_table'}
));
/*+------+--------+
| NODE | DEGREE |
|------+--------+
| Empty table. |
+------+--------+ */
-- Note that the columns of the result table are given the generic names
-- COL1 and COL2, instead of NODE and DEGREE.
SELECT * FROM my_result_table;
/*+------+------+
| COL1 | COL2 |
|------+------+
| 1 | 1 |
| 2 | 2 |
| 3 | 1 |
+------+------+ */When you send the results of an algorithm to a Snowflake table
using the result_table argument, the provided table is either created
if it does not already exist, or is replaced with the new results.
The columns of the table are given generic names, such as COL1 and COL2.
All data sent to a table using the result_table argument
are converted to text.
The result_table argument is necessary for storing results of an
algorithm executed in a scheduled task.
The table generated with result_table loses the algorithm’s schema and is not well suited for storing intermediate results in multi-step workloads.
Using the CREATE TABLE command is a better option.
Multi-Step Workloads
Storing the results returned by an algorithm in a Snowflake table allows you to work with the results in other queries. In particular, you may create multi-step graph workloads that build off previous results.
For example, the following snippet computes the PageRank of the neighbors of a particular node:
-- Create an undirected graph with three nodes and two edges.
CREATE TABLE my_edges(x INT, y INT) AS SELECT * FROM VALUES (1, 2), (2, 3);
CALL RAI.create_data_stream('my_edges');
CALL RAI.create_graph('my_graph', 'my_edges');
-- Find the neighbors of node 2 in `'my_graph'` and store the results
-- in a table called `neighbor_results`.
CREATE OR REPLACE TABLE neighbor_results(node1 INT, node2 INT) AS (
SELECT * FROM TABLE(RAI.neighbor('my_graph', {'node': 2}))
)
-- Compute the PageRank of the neighbors of node 2. The array of
-- neighbors is built from the `neighbor_results` table.
SELECT * FROM TABLE(RAI.pagerank('my_graph', {
'node': (SELECT array_agg(node2) FROM neighbor_results)
}));
/*+------+--------------+
| NODE | VALUE |
|------+--------------+
| 1 | 0.2567563672 |
| 3 | 0.2567563672 |
+------+--------------+ */
-- Remove the intermediate results table.
DROP TABLE neighbor_results;In the preceding example, the array provided to the
pagerank
function’s node argument
is prepared by selecting the neighbor_results table’s node2 column
and using Snowflake’s built-in
array_agg (opens in a new tab)
function to build an array.
Examples
This section illustrates the concepts described in Executing Algorithms and Working With Results using several examples of common scenarios.
Plot a Degree Histogram
Viewing a graph’s degree histogram shows you how the degrees are distributed among nodes and may provide some insight into the structure of the graph.
You can count the number of nodes with each degree in a graph using the
degree_histogram
function:
USE ROLE my_sf_role;
USE WAREHOUSE my_sf_warehouse;
USE DATABASE my_sf_database;
CREATE OR REPLACE SCHEMA degree_histogram;
USE SCHEMA degree_histogram;
-- Set the RAI context.
CALL use_rai_engine('my_rai_engine');
CALL use_rai_database('my_rai_db');
-- Create an undirected graph.
CREATE OR REPLACE TABLE my_edges(node1 INT, node2 INT) AS (
SELECT * FROM VALUES
(1, 2), (1, 3), (1, 4), (1, 5), (1, 6), (2, 3),
(2, 6), (3, 7), (4, 5), (4, 8), (5, 9)
);
CALL RAI.create_data_stream('my_edges');
CALL RAI.create_graph('my_graph', 'my_edges');
-- Count the number of nodes with each degree.
SELECT * FROM TABLE(RAI.degree_histogram('my_graph'));
/*+--------+-------+
| DEGREE | COUNT |
|--------+-------+
| 1 | 3 |
| 2 | 1 |
| 3 | 4 |
| 5 | 1 |
+--------+-------+ */To view a histogram, click Chart above the results
table for your query.
You can use the configuration options on the right-hand panel to view
the results as a bar chart with bars from the COUNT column plotted
against the DEGREE column on the X-Axis:
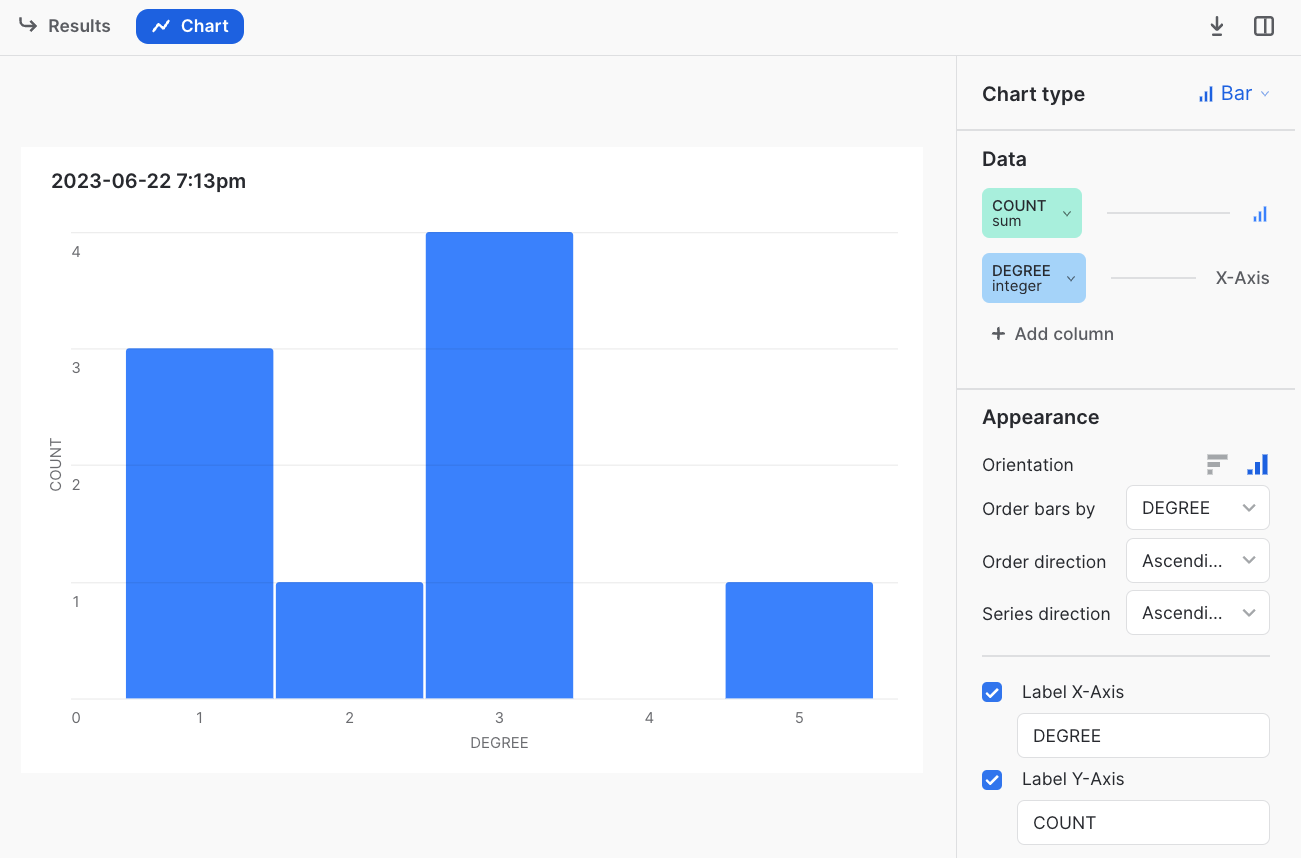
You may customize the histogram using the Snowflake UI, including adding buckets. See Visualizing Worksheet Data (opens in a new tab) in the Snowflake documentation for more details.
Rank Nodes by Centrality
Centrality algorithms are used to measure a node’s importance or influence in a graph. The RAI SQL Graph Library implements several centrality algorithms, including:
This example uses the eigenvector_centrality function to sort a subset of nodes in the graph by importance.
However, you can replace it with any of the other centrality functions.
The example illustrates concepts such as
array arguments
and working with
results schema.
USE ROLE my_sf_role;
USE WAREHOUSE my_sf_warehouse;
USE DATABASE my_sf_database;
CREATE OR REPLACE SCHEMA centrality_rank;
USE SCHEMA centrality_rank;
-- Set the RAI context.
CALL RAI.use_rai_database('my_rai_db');
CALL RAI.use_rai_engine('my_rai_engine');
-- Create an undirected graph with five nodes and five edges.
-- Visually, the graph looks like: 1 -- 3 -- 5
-- | |
-- 2 -- 4
CREATE OR REPLACE TABLE my_edges(node1 INT, node2 INT)
AS (
SELECT * FROM VALUES
(1, 2), (1, 3), (2, 4), (3, 4), (3, 5)
);
CALL RAI.create_data_stream('my_edges');
CALL RAI.create_graph('my_graph', 'my_edges');
-- Sort nodes 1, 3, and 5 by their eigenvector centrality.
-- from highest to lowest.
SELECT node
FROM TABLE(RAI.eigenvector_centrality(
'my_graph', {'node': [1, 3, 5]}
))
ORDER BY value DESC;
/*+------+
| NODE |
|------+
| 3 |
| 1 |
| 5 |
+------+ */You can find more information about centrality algorithms in the Centrality section of the Overview of Graph Algorithms.
Find Similar Nodes
The RAI SQL Graph Library implements several similarity algorithms, including:
This example uses the jaccard_similarity function to find
the most similar node that is not a neighbor of a given node.
However, you can replace it with any of the other similarity functions.
USE ROLE my_sf_role;
USE WAREHOUSE my_sf_warehouse;
USE DATABASE my_sf_database;
CREATE OR REPLACE SCHEMA similar_nodes;
USE SCHEMA similar_nodes;
-- Set the RAI context.
CALL RAI.use_rai_database('my_rai_db');
CALL RAI.use_rai_engine('my_rai_engine');
-- Create an undirected graph with five nodes and five edges.
-- Visually, the graph looks like: 1 -- 3 -- 5
-- | |
-- 2 -- 4
CREATE OR REPLACE TABLE my_edges(node1 INT, node2 INT) AS (
SELECT * FROM VALUES
(1, 2), (1, 3), (2, 4), (3, 4), (3, 5)
);
CALL RAI.create_data_stream('my_edges');
CALL RAI.create_graph('my_graph', 'my_edges');
-- Compute the most similar node to node 1 that is not already a neighbor of node 1.
SELECT jacc.node2
FROM
TABLE(RAI.jaccard_similarity('my_graph', {'node1': 1})) as jacc
WHERE
jacc.node2 NOT IN (
SELECT node2 FROM TABLE(RAI.neighbor('my_graph', {'node1': 1}))
)
AND jacc.node2 != 1
ORDER BY jacc.score DESC LIMIT 1;
/*+------------+
| JACC.NODE2 |
|------------+
| 4 |
+------------+ */See Also
See Managing Graphs to learn more about creating and managing graphs. See the Overview of Graph Algorithms to explore every algorithm in RelationalAI’s SQL Graph Library for Snowflake.