Control Relations
This concept guide explains what control relations are, what they do, and how they’re used within the system.
Introduction
In the database management systems, multiple types of commands are needed to be able to define, manipulate, and query data as well as to control transactions, which contain the command the database engine should execute.
In Rel — RelationalAI’s declarative modeling language — data are organized using relations.
Data are stored in base relations. Logical rules are expressed using relations. Modules and integrity constraints are special types of relations. Going a step further, relations are also used to communicate commands to the database that need to be executed. These types of relations are called control relations.
Control relations are relations that communicate commands to the system that change the state of the database, control the database transaction, or have other external side effects.
The following relations are considered control relations:
| Relation | Description |
|---|---|
insert | Adds data into the system. |
delete | Removes data from the system. |
abort | Aborts a transaction. |
output | Requests data. |
export | Exports data. |
rel:config | Modifies system behaviors. |
Communicating these commands via control relations, rather than dedicated Rel keywords, opens up many new possibilities. In particular, it allows you to write logic that may be recursive (useful for logging activities) or that depends on other control relations (for example, automated data export triggered by data manipulation).
insert - Adding Data
You can use the relation insert to add data into a base relation.
If the base relation doesn’t exist, it will be created.
The control relation insert has the same purpose as the SQL INSERT command.
Other than the side effect of updating base relations, insert is defined as any other Rel relation.
The right-hand side of the definition may consist of just literals (inserting concrete data values) or may be a complex logical rule (or relational expression).
For instance, consider inserting customer ages into the base relation customer_age, where customer_age(x, y) states the age, y, of the customer, x:
// write query
def insert[:customer_age] = {("john", 20); ("jack", 17); ("jill", 40)}
def output[:insert] = insert
def output[:customer_age] = customer_ageNow, say you want to define a rule for customers of adult age through the base relation adult:
// write query
def insert(:adult, x) { customer_age[x] > 18 }
def output[:insert] = insert
def output[:adult] = adultThe output shows how the content of insert gets translated into the relation adult.
Note that rule definitions of insert that don’t start with a Symbol have no effect in the database.
This usage is not recommended.
delete - Removing Data
You can use the relation delete to remove data from the system.
It works similarly to insert, and therefore, apart from deleting base relations, it follows all Rel constructs.
The control relation delete has the same purpose as the SQL DELETE command.
Back to the example above, consider removing a customer from the base relation customer_age:
// write query
def delete[:customer_age] = {"jack", 17}
def output[:delete] = delete
def output[:customer_age] = customer_ageOr say you delete the entire content of a base relation:
// write query
def delete[:customer_age] = customer_age
def output = customer_ageThe output confirms that customer_age is now an empty relation, i.e., the empty set.
abort - Canceling a Transaction
You can use the relation abort to abort an ongoing transaction.
If abort is set to true, the transaction will be aborted.
For instance, say you want to insert the relation friends as a base relation into the database as follows:
// write query
def insert[:friends] = {("Mike", "Anna"); ("Zoe", "Jenn")}
def abort = true
def output = friendsEven though you’re performing a write transaction, the database state hasn’t been modified because of abort = true.
The system still returns the updated content of friends but this change hasn’t been persisted in the database and is only transitory within the lifetime of this transaction.
You can confirm this by querying friends in a subsequent transaction.
See how friends is still an empty relation:
// write query
def output = friendsAny other value of abort — like abort = false or abort = 1 — doesn’t lead to a cancellation of the transaction.
The relation abort is used for integrity constraint violations to prevent database changes that can violate the integrity contraints defined in the database.
output - Requesting Data
You can use the relation output to return query results.
It’s not recommended to include a declaration for output in a Rel model.
Otherwise, whenever a query is executed, the returned results will include the content of this installed declaration.
The next two sections explain how the content of output is delivered to users of different platforms.
Console
In the RAI Console, the visualization of output is automatic and uses the MIME (opens in a new tab) information, if present, to display the content in a user-friendly way.
Here’s an example of how to display a type- and arity-overloaded relation:
// read query
def output[1] = "2022-12-31"
def output[2] = ^Date[2022, 12, 31]
def output[3] = 2022, 12, 31Additionally, Rel provides a Visualization Library with some built-in relations that allows users to enhance data with MIME types.
For example, you can use the relation markdown to render a string as Markdown:
// read query
def text = """
### Motivation
I like using Markdown and its _highlighting_ features.
"""
def output = ::std::display::markdown[text]Rel also offers the capabilities to create graphical data representations and visualize graphs. See the Data Visualization guides for more details.
RelationalAI SDKs
When working with the RelationalAI SDKs, the display of output isn’t handled automatically and you have to call a specific function for it, depending on the language used.
For instance, you can print the results from output using the RelationalAI SDK for Python as follows:
>>> rsp = api.exec(ctx, database, engine, "def output = {1; 2; 3}")
>>> show.results(rsp)// output (Int64)
1;
2;
3export - Exporting Data
You can use the relation export to export data from the system, for instance, to one of the supported cloud providers.
A data export is triggered when the relation export is properly populated.
To export CSV files, you can use export_csv,
which takes as input a configuration relation that defines all the required options.
This is also the case with JSON files and export_json.
See the Data Import and Export guides for more details.
Simple Example
Here’s an example exporting the data_csv relation, which contains country names and their corresponding capital cities:
// read query
def data_csv = load_csv[(:data,"""
country,capital
USA,"Washington, D.C."
France,Paris
Egypt,Cairo
""")]
module config
def data = data_csv
def path = "azure://myaccount.blob.core.windows.net/sascontainer/myfile.csv"
module integration
def provider = "azure"
def credentials = (:azure_sas_token, raw"my_azure_credentials")
end
end
def export = export_csv[config]The generated myfile.csv file for this example reads:
capital,country
"Washington, D.C.",USA
Paris,France
Cairo,EgyptAdvanced Example
A more advanced usage of export could be an automated data export, triggered by data changes within the database.
For example, you want to export the relation data_csv every time the relation is updated.
You can do this by loading the following model into the database:
// model
module config
def data = data_csv
def path = "azure://myaccount.blob.core.windows.net/sascontainer/myfile.csv"
module integration
def provider = "azure"
def credentials = (:azure_sas_token, raw"my_azure_credentials")
end
end
def export(x...) {
export_csv[config](x...)
and (exists(insert[:data_csv]) or exists(delete[:data_csv]))
}The condition (exists(insert[:data_csv]) or exists(delete[:data_csv])) ensures that the data export only happens when a transaction tries to insert or delete data into data_csv.
For example, say you add an entry for Spain and remove the existing one for France:
// write query
def to_add = {
(:country, 4, "Spain");
(:capital, 4, "Madrid")
}
def to_remove = {
(:country, 2, "France");
(:capital, 2, "Paris")
}
def insert[:data_csv] = to_add
def delete[:data_csv] = to_removeAfter you’ve performed this write query, you’ll notice that the exported myfile.csv in your cloud storage has also been updated accordingly and now reads:
capital,country
"Washington, D.C.",USA
Cairo,Egypt
Madrid,Spainrel:config - Setting System Behaviors
You can use the relation rel:config to change certain system behaviors.
The following options can be configured:
| Option | Description |
|---|---|
:abort_on_error | Aborts transactions that contain errors. |
:disable_integrity_constraints | Deactivates integrity constraints. |
:disable_ivm | Deactivates the Incremental View Maintenance (IVM). |
:eager_maintenance | Sets eager maintenance for all derived relations. |
Options are specified using the RelName data type.
For instance, you can permanently set the :abort_on_error option by performing the following write query:
// write query
def insert[:rel, :config] = :abort_on_errorTo disable it again permanently, use the delete command within a write query:
// write query
def delete[:rel, :config] = :abort_on_errorThe control relations insert and delete must always be used to configure all options in rel:config, even for temporary changes within read queries.
The options are discussed in detail below.
:abort_on_error
In general, a transaction only aborts if there is an exception or an IC violation.
When :abort_on_error is added to rel:config, the system also aborts a transaction when an error occurs.
For instance, consider the following query:
// read query
def R = {1; 2; 3
def output = RThe output is not showing since there is a parse problem, i.e., the ending curly bracket is missing.
However, the transaction is not aborted and shows COMPLETED status.
You can inspect specific transactions using the RAI Console:
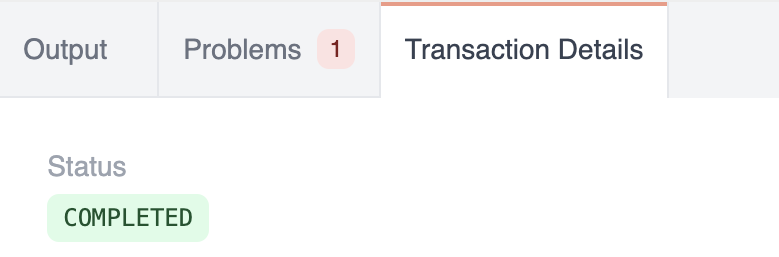
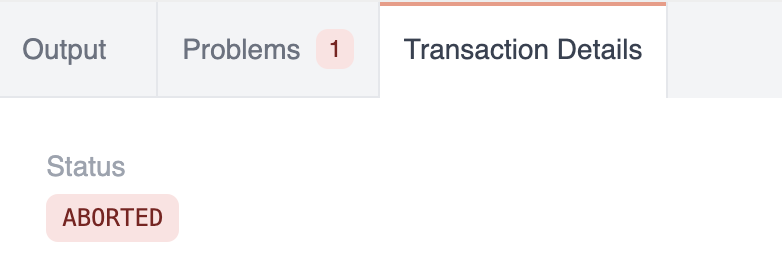
If you now set rel:config:abort_on_error, the transaction is aborted.
// write query
def insert[:rel, :config] = :abort_on_errorYou can see this in the Transaction Details tab in the Console:
You can disable this behavior by deleting that configuration:
// write query
def delete[:rel, :config] = :abort_on_error:disable_integrity_constraints
You can disable integrity constraints (ICs) by adding the :disable_integrity_constraints option to rel:config.
In this way, the system ignores all ICs installed in the system.
For instance, consider the following code:
// read query
def R = {1; 2; 3}
ic { count[R] = 7 }The IC declaration above forces the relation R to contain seven tuples, using the built-in Rel relation count.
The IC is violated, since R only contains three tuples:
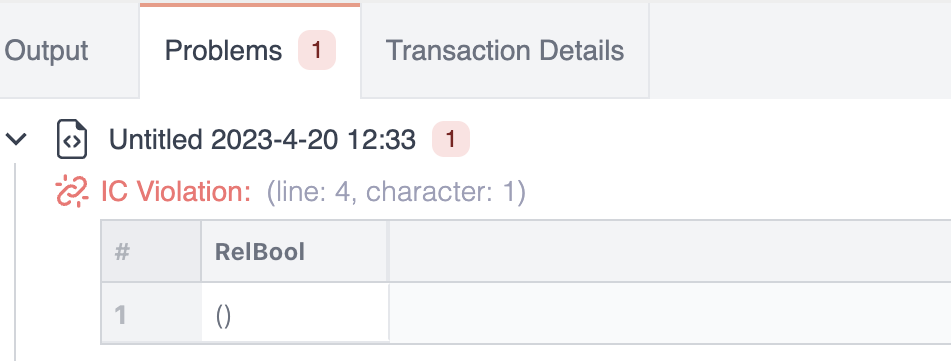
You can deactivate ICs for an individual read query:
// read query
def insert[:rel, :config] = :disable_integrity_constraints
def R = {1; 2; 3}
ic { count[R] = 7 }For every subsequent query, the abort on integrity constraint violations is enabled again. To disable it permanently, you need to perform a write query.
// write query
def insert[:rel, :config] = :disable_integrity_constraintsYou can reenable ICs permanently by deleting the option again:
// write query
def delete[:rel, :config] = :disable_integrity_constraints:disable_ivm
The RKGS evaluates queries incrementally. This means that as you add, change, or remove data from your database, the computational cost of the update scales only with the size of the update and not with the size of your dataset. This paradigm makes intermediate result materialization much less expensive. This is called Incremental View Maintenance (IVM).
IVM with demand-driven maintenance is enabled by default.
You can change this behavior by adding the :disable_ivm option:
// write query
def insert[:rel, :config] = :disable_ivmYou can reenable it globally by deleting that configuration:
// write query
def delete[:rel, :config] = :disable_ivmYou can also use the following two annotations to control the application of IVM:
| Annotation | Description |
|---|---|
@nomaintain | Disables IVM for a definition. |
@maintained | Expresses the expectation that a definition should be maintained. Results in an error if IVM does not support this definition. |
:eager_maintenance
There are two ways to implement IVM:
| Maintenance | Description |
|---|---|
| Eager | The derived relation, i.e., materialized view, is updated in the same transaction. |
| Demand-driven | The materialized view is updated after the transaction is commited and only when it is accessed. For instance, as a response to a query. |
By default, the RKGS performs IVM with demand-driven maintenance.
You can change this behavior by modifying the :eager_maintenance option.
When adding it to rel:config, all derived relations are eagerly maintained:
// write query
def insert[:rel, :config] = :eager_maintenanceYou can reenable the default configuration by:
// write query
def delete[:rel, :config] = :eager_maintenanceYou can also apply it locally to a certain model by using the annotation @eager_maintenance in the model declaration:
// model
@eager_maintenance def R = {1; 2; 3}The :eager_maintenance option only makes sense for installed derived relations. For derived relations defined within queries, there is no maintenance and base relations are always updated with each write query.
Summary
Control relations are a special type of relation that can change the state of the database (insert and delete), control database transactions (abort), control system behaviors (rel:config), or have other side effects like controlling external data flows (output and export).